Semantic Similarity of Short Texts
(Kesamaan
semantik pendek Teks)
Abstrak
Makalah
ini menyajikan metode untuk mengukur Kesamaan Semantik dari Teks Pendek menggunakan
kumpulan tulisan berdasarkan dari kemiripan kata semantic, versi normalisasi
dan modifikasi dari algoritma pencocokan string Longest Common Subsequences (LCS) B) algoritma string matching. Metode
yang ada untuk kesamaan komputasi teks telah difokuskan terutama pada salah
satu dokumen besar atau kata-kata individu. Dalam tulisan ini, kita fokus pada
komputasi kesamaan antara dua kalimat atau antara dua paragraf pendek. Metode
yang diusulkan dapat dimanfaatkan dalam berbagai aplikasi yang melibatkan representasi
pengetahuan tekstual dan penemuan pengetahuan. Hasil evaluasi pada dua set data
yang berbeda menunjukkan bahwa metode kami melebihi beberapa metode bersaing.
Kata Kunci
Kesamaan semantik kata-kata,
kesamaan teks singkat, corpus- langkah-langkah berdasarkan.
1. Pengantar
Kesamaan adalah
sebuah konsep yang kompleks yang telah banyak dibahas dalam masyarakat teori
linguistik, filsafat, dan informasi. Frawley [9] membahas semua mengetik
semantik dalam hal dua mekanisme: deteksi persamaan dan perbedaan. Untuk tugas
kami, mengingat dua segmen teks input, kami ingin untuk secara otomatis
menentukan skor yang menunjukkan kesamaan mereka di semantik tingkat, sehingga
melampaui metode pencocokan leksikal sederhana tradisional digunakan untuk
tugas ini.
Sebuah metode
yang efektif untuk menghitung kesamaan antara teks singkat atau kalimat
memiliki banyak aplikasi dalam pengolahan dan bidang terkait bahasa alami
seperti pencarian informasi dan penyaringan teks. Misalnya, di halaman
pencarian web, kesamaan teks telah terbukti menjadi salah satu teknik terbaik
untuk meningkatkan efektivitas pengambilan [33] dan dalam pengambilan gambar
dari Web, penggunaan teks singkat seputar gambar dapat mencapai presisi
pengambilan lebih tinggi dari penggunaan seluruh dokumen yang gambar tertanam
[3]. Penggunaan kesamaan teks bermanfaat untuk umpan balik relevansi dan
kategorisasi teks [13], [24], summarization teks [7], [22], disambiguasi makna
[19], metode untuk evaluasi otomatis mesin terjemahan [25], [ 31], evaluasi
koherensi teks [17], dan skema yang cocok dalam database [26].
Salah satu
kelemahan utama dari sebagian besar metode yang ada adalah domain
ketergantungan: sekali metode kesamaan dirancang untuk domain aplikasi
tertentu, tidak dapat disesuaikan dengan mudah ke domain lain. Untuk mengatasi
kelemahan ini, kami bertujuan untuk mengembangkan metode yang sepenuhnya
otomatis dan independen dari domain dalam aplikasi membutuhkan teks atau kalimat
kecil kesamaan ukuran. Komputasi kesamaan teks dapat dilihat sebagai komponen
generik untuk komunitas riset berurusan dengan text terkait representasi
pengetahuan dan penemuan.
Makalah ini
disusun sebagai berikut: Bagian 2 menyajikan gambaran singkat tentang kerja
terkait. Metode kami diusulkan dijelaskan dalam Bagian 3. Evaluasi dan hasil
eksperimen dibahas dalam Bagian 4.
2. Pekerjaan yang berhubungan
Ada literatur
yang luas pada pengukuran kesamaan antara teks-teks panjang atau dokumen [15],
[27], [28], tetapi ada sedikit pekerjaan yang berhubungan dengan pengukuran
kesamaan antara kalimat atau teks pendek [8]. pekerjaan yang berhubungan secara
kasar dapat diklasifikasikan ke dalam empat kategori utama: kata co-kejadian /
metode berbasis vektor model dokumen, metode berbasis corpus, metode hibrida,
dan deskriptif metode fitur berbasis.
Metode model
dokumen berbasis vektor yang umum digunakan dalam Information Retrieval (IR)
sistem [28], di mana dokumen yang paling relevan dengan query masukan
ditentukan oleh mewakili dokumen sebagai vektor kata, dan kemudian query
dicocokkan dengan dokumen sejenis di database dokumen melalui metrik kesamaan [37].
The Latent
Semantic Analysis (LSA) [15], [16] dan Hyperspace Analoginya ke Bahasa (HAL)
Model [2] dua metode terkenal di kesamaan berbasis corpus. LSA analisis korpus
besar teks bahasa alami dan menghasilkan representasi yang menangkap kesamaan
kata dan bagian-bagian teks. Dimensi dari kata dengan matriks konteks terbatas
untuk beberapa ratus karena batas komputasi Dekomposisi Nilai Singular (SVD).
Akibatnya vektor adalah tetap dan representasi teks pendek sangat jarang.
Metode HAL menggunakan leksikal co-kejadian untuk menghasilkan ruang semantik
dimensi tinggi. hasil eksperimen penulis menunjukkan bahwa HAL itu tidak
menjanjikan sebagai LSA dalam perhitungan kesamaan untuk teks singkat.
Metode Hybrid
menggunakan kedua tindakan berbasis corpus [38] dan berbasis pengetahuan
langkah-langkah [18] kata kesamaan semantik untuk menentukan kesamaan teks.
Mihalcea et al. [30] menyarankan metode gabungan untuk mengukur kesamaan
semantik teks dengan memanfaatkan informasi yang dapat ditarik dari kemiripan
kata-kata komponen. Secara khusus, mereka menggunakan dua langkah berbasis
corpus, PMI-IR (pointwise Mutual Informasi dan Information Retrieval) [38] dan
LSA (Latent Semantic Analysis) [16] dan enam berbasis pengetahuan
langkah-langkah [12], [18], [19 ], [23], [34], [39] kata semantik kesamaan, dan
menggabungkan hasil untuk menunjukkan bagaimana langkah-langkah ini dapat
digunakan untuk memperoleh kesamaan text-to-text metrik. Mereka mengevaluasi
metode mereka pada tugas pengakuan parafrase. Kelemahan utama dari metode ini
adalah bahwa hal itu menghitung kesamaan kata-kata dari delapan metode yang
berbeda, yang tidak efisien secara komputasi.
Li et al. [20]
mengusulkan metode hybrid lain yang berasal kesamaan teks dari informasi
semantik dan sintaksis yang terdapat dalam teks dibandingkan. Metode yang
diusulkan mereka secara dinamis membentuk kata patungan didirikan hanya
menggunakan semua kata yang berbeda dalam pasang kalimat. Untuk setiap kalimat,
vektor semantik baku berasal dengan bantuan dari WordNet basis data leksikal
[32]. Sebuah vektor urutan kata dibentuk untuk setiap kalimat, lagi menggunakan
informasi dari database leksikal. Karena setiap kata dalam kalimat kontribusi
berbeda terhadap makna seluruh kalimat, arti dari sebuah kata tertimbang dengan
menggunakan konten informasi yang diperoleh dari corpus a. Dengan menggabungkan
vektor semantik mentah dengan konten informasi dari korpus, vektor semantik
diperoleh untuk masing-masing dua kalimat. kesamaan semantik dihitung
berdasarkan dua vektor semantik. Kesamaan rangka dihitung dengan menggunakan
dua vektor pesanan. Akhirnya, kesamaan kalimat diperoleh dengan menggabungkan
kesamaan semantik dan ketertiban kesamaan.
metode berbasis
fitur mencoba untuk mewakili kalimat menggunakan seperangkat fitur yang telah
ditetapkan. Kesamaan antara dua teks diperoleh melalui classifier terlatih.
Tapi menemukan fitur yang efektif dan memperoleh nilai-nilai untuk fitur ini
dari kalimat membuat kategori ini dari metode yang lebih praktis.
3. Metode yang diusulkan
Metode yang diusulkan berasal
kesamaan teks dua teks dengan menggabungkan semantik kesamaan dan kesamaan
string, dengan normalisasi. Kami menyebutnya metode yang diusulkan kami metode
Semantic Text Similarity (STS). Kami menyelidiki pentingnya termasuk kesamaan
string dengan contoh sederhana. Mari kita mempertimbangkan sepasang teks,
sepasang teks, sepasang teks, sepasang teks, sepasang teks, sepasang teks,
sepasang teks, sepasang teks, sepasang teks, T 1 dan T 2 yang berisi yang
berisi yang berisi yang berisi yang berisi yang berisi yang berisi yang berisi
yang berisi kata benda (nama yang tepat) kata benda (nama yang tepat) kata
benda (nama yang tepat) kata benda (nama yang tepat) kata benda (nama yang
tepat) kata benda (nama yang tepat) kata benda (nama yang tepat) kata benda
(nama yang tepat) kata benda (nama yang tepat) 'Maradona' di 'Maradona' di
'Maradona' di 'Maradona' di 'Maradona' di 'Maradona' di 'Maradona' di
'Maradona' di 'Maradona' di T 1.
Di T 2 nama 'Maradona' adalah
salah eja untuk 'Maradena'.
T 1: Banyak yang menganggap Maradona sebagai
pemain terbaik dalam sejarah sepak bola.
T 2: Maradena adalah salah satu pemain sepak bola terbaik. kamus berbasis ukuran kesamaan tidak dapat memberikan nilai kesamaan antara dua nama yang tepat tersebut. Dan kesempatan untuk mendapatkan nilai kemiripan menggunakan langkah-langkah kesamaan berdasarkan corpus- sangat rendah. Kami memperoleh skor kesamaan baik jika kita menggunakan langkah-langkah kesamaan tali. Bagian berikut menyajikan penjelasan rinci dari masing-masing fungsi yang disebutkan di atas.
T 2: Maradena adalah salah satu pemain sepak bola terbaik. kamus berbasis ukuran kesamaan tidak dapat memberikan nilai kesamaan antara dua nama yang tepat tersebut. Dan kesempatan untuk mendapatkan nilai kemiripan menggunakan langkah-langkah kesamaan berdasarkan corpus- sangat rendah. Kami memperoleh skor kesamaan baik jika kita menggunakan langkah-langkah kesamaan tali. Bagian berikut menyajikan penjelasan rinci dari masing-masing fungsi yang disebutkan di atas.
3.1 String Kesamaan antara Kata-kata
Kami menggunakan subsequence umum
terpanjang ( LCS) [1], [14] ukuran dengan beberapa normalisasi dan kecil
modifikasi untuk mengukur kesamaan string kami. Kita gunakan tiga versi
modifikasi yang berbeda dari SKB dan kemudian mengambil jumlah tertimbang ini
1. Melamed [29] SKB dinormalisasi dengan membagi panjang umum terpanjang
subsequence dengan panjang lagi tali dan menyebutnya Rasio subsequence umum
terpanjang (LCSR). Tapi LCSR tidak memperhitungkan dari panjang string pendek
yang kadang-kadang memiliki dampak yang signifikan pada skor kesamaan.
Kami
menormalkan subsequence umum terpanjang (SKB) sehingga memperhitungkan panjang
dari kedua pendek dan panjang tali dan menyebutnya normalisasi subsequence umum
terpanjang ( NLCS) yang,
Sementara di LCS klasik, subsequence umum kebutuhan tidak berturut-turut, dalam pencocokan teks, subsequence umum berturut-turut adalah penting untuk tingkat tinggi yang cocok. Kita gunakan maksimal berturut-turut subsequence umum terpanjang mulai dari karakter 1, v 2 = MCLCS
1 ( Ara. 1) dan maksimal
berurutan terpanjang umum subsequence mulai dari karakter apapun n, v 3 = MCLCS
n (Gambar. 2). Dalam Gambar. 1, kami menyajikan sebuah algoritma yang mengambil
dua string sebagai masukan dan mengembalikan string pendek atau bagian maksimal
berturut-turut lebih pendek string yang berturut-turut pertandingan dengan
string lagi, mana yang cocok harus dari karakter pertama (karakter 1) untuk
kedua string. Dalam Gambar. 2, kami menyajikan algoritma lain di mana
pencocokan mungkin mulai dari karakter (karakter n). Kami juga menormalkan Kami
juga menormalkan MCLCS 1 dan MCLCS Kami
mengambil jumlah tertimbang dari nilai-nilai v 1, v 2, dan v 3 untuk menentukan
nilai kesamaan tali di mana w 1, w 2, w 3 adalah bobot dan w 1+ w 2+ w 3 = 1.
Oleh karena itu, kesamaan dari dua string adalah: α = w 1 v 1 + w 2 v 2 + w 3 v
3 (2) Kami menetapkan bobot yang sama untuk eksperimen kami. 2 algoritma MCLCS
1 Memasukkan: r saya, s j // r saya dan s j dua string masukan mana dua string //
| r i | = τ, | s j | = η dan τ ≤ η seperti yang disebutkan sebelumnya.
1. τ ← | r i |, η ← | s j |
2. sementara | sementara |
sementara | sementara | sementara | sementara | r i | > 0
3. jika r saya ⊂
s j // yaitu, yaitu, yaitu, yaitu, yaitu, yaitu, yaitu, yaitu, yaitu, yaitu,
yaitu, yaitu, yaitu, yaitu, s j ∩ r i = r
4. kembali r saya
5. lain r saya ← r i \ c τ //
yaitu, menghapus kanan paling karakter // dari r saya
6. berakhir jika
7. mengakhiri
sementara Output: r saya // r
saya adalah maksimal Berturut-turut //
Gambar. 1. LCS maksimal
berturut-turut mulai dari karakter 1. 1 Kami menggunakan versi modifikasi
karena dalam percobaan kami kami memperoleh hasil yang lebih baik (presisi dan
recall) untuk pencocokan teks pada sampel data daripada ketika menggunakan asli
SKB, atau tindakan kesamaan string lainnya. 2 Kami menggunakan bobot yang sama
di beberapa tempat dalam makalah ini untuk menjaga sistem tanpa pengawasan.
Jika data pembangunan akan tersedia, kita bisa menyesuaikan bobot.
algoritma MCLCS n
Memasukkan: r saya, s j// r saya
dan s j dua string masukan mana // | r i | = τ, | s j | = η dan τ ≤ η.
1. sementara | | r i | > 0
2. menentukan semua n gram dari r saya dimana n
= 1 .. | r i | dan sayar adalah himpunan n gram
3. jika x ∈ S j di mana
{ di mana { x | saya rx ∈, x = Max ( saya r)} // saya
adalah jumlah n gram dan Max ( gram dan Max ( saya r) // mengembalikan panjang
maksimum n gram dari saya r
4. kembali x
5. lain saya r ← saya r \ x //
menghapus x dari set saya r
6. berakhir jika
7. mengakhiri sementara
Output: x// x adalah maksimal
Berturut-turut // LCS mulai karakter apapun n.
algoritma semanticMatching
Memasukkan: r saya, s j// mana |
r i | = τ, | s j | = η dan τ ≤ η.
1. v ← SOCPMI ( r saya, s j) // Metode
ini mennetukan // kesamaan semantik antara dua kata. Setiap // metode kesamaan
lain juga dapat digunakan sebagai pengganti.
2. jika v> λ // λ adalah
maksimum yang mungkin nilai-nilai kesamaan
3. v ← 1
4. lain v ← v / λ
5. akhir jika
Output: v // v adalah semantik
nilai kemiripan // antara 0 dan 1, inklusif
3.2 Kesamaan semantik antara Kata-kata
Ada jumlah yang relatif besar
kata-to-kata metrik kesamaan dalam literatur, mulai dari langkah-langkah yang
berorientasi jarak-dihitung pada jaringan semantik atau pengetahuan mendasarkan
(atau kamus / tesaurus berbasis langkah-langkah), untuk metrik berdasarkan
model teori informasi (atau tindakan berbasis corpus) belajar dari koleksi teks
besar. Sebuah tinjauan rinci pada kata kesamaan dapat ditemukan di [21], [35].
Kami fokus perhatian kita pada langkah-langkah berdasarkan corpus- karena
cakupan tipe besar mereka.
PMI-IR [38]
adalah sebuah metode sederhana untuk menghitung kesamaan berbasis corpus
kata-kata yang menggunakan pointwise Reksa Informasi. PMI-IR digunakan
AltaVista Pencarian sintaks query untuk menghitung probabilitas. LSA, ukuran
berbasis corpus lain, analisis korpus besar teks alami dan menghasilkan
representasi yang menangkap kesamaan kata (dibahas pada bagian Kerja Terkait).
Kami menggunakan
Orde Kedua Co-kejadian PMI (SOC- PMI) metode kata kesamaan [10] yang
menggunakan pointwise Reksa Informasi untuk mengurutkan daftar kata tetangga
penting dari dua kata target dari corpus besar. Metode itu menganggap kata-kata
yang umum di kedua daftar dan agregat nilai PMI mereka (dari daftar berlawanan)
untuk menghitung kesamaan semantik relatif. Kami mendefinisikan pointwise
informasi mutual Fungsi
hanya kata-kata yang memiliki f b ( t saya, w) > 0
dimana f t ( t
saya) memberitahu kita berapa kali jenis t saya muncul di seluruh corpus, f b (
t saya, w) memberitahu kita berapa kali kata muncul dengan kata w dalam kata-kata
jendela konteks dan m adalah jumlah total token di korpus. Sekarang, untuk kata
untuk kata untuk kata untuk kata untuk kata untuk kata w 1, kita mendefinisikan
satu set kata-kata, kita mendefinisikan satu set kata-kata, X, diurutkan dalam
urutan dengan nilai-nilai PMI mereka dengan w 1 dan diambil paling atas β 1
kata memiliki f pmi ( t saya, w 1) > 0.
X = {X saya},
dimana dimana dimana dimana dimana dimana dimana dimana i = 1, 2, β 1 dan f pmi
( t 1, w 1) ≥ f pmi ( t 2, w 1) ≥ ... f pmi ( t β1- 1, w 1) ≥ f pmi ( t β1, w
1)
Demikian pula,
untuk kata w 2, kita mendefinisikan satu set kata-kata, Y, diurutkan dalam
urutan dengan nilai-nilai PMI mereka dengan w 2 dan diambil paling atas β 2
kata memiliki kata f pmi ( t saya, w 2) > 0. Nilai β
(antara β 1 atau β 2) terkait dengan berapa
kali kata w muncul dalam korpus, yaitu, frekuensi w serta jumlah jenis dalam
korpus. Kemudian kita mendefinisikan beta-PMI penjumlahan fungsi. kata demi
kata w 1,
itu beta-PMI penjumlahan Fungsi
adalah:
f w f X w β γ β = = Σ dimana, dan
2 ( . ) 0 pmi saya f X w > 1 ( . ) 0 pmi saya f X w>
yang merangkum semua nilai PMI
positif dari kata-kata dalam set Y juga umum untuk kata-kata dalam set X. Dengan
kata lain, fungsi ini sebenarnya mengumpulkan nilai-nilai PMI positif dari
semua kata-kata semantic penutupan penutupan penutupan penutupan penutupan
penutupan penutupan penutupan penutupan w 2 yang juga umum di yang juga umum di
yang juga umum di yang juga umum di yang juga umum di yang juga umum di yang
juga umum di yang juga umum di yang juga umum di w 1 'Daftar s. Semakin tinggi
nilai 'Daftar s. Semakin tinggi nilai 'Daftar s. Semakin tinggi nilai 'Daftar
s. Semakin tinggi nilai 'Daftar s. Semakin tinggi nilai 'Daftar s. Semakin
tinggi nilai 'Daftar s. Semakin tinggi nilai 'Daftar s. Semakin tinggi nilai
'Daftar s. Semakin tinggi nilai γ adalah, adalah, adalah, adalah, adalah,
adalah, adalah, adalah, adalah, penekanan lebih besar pada kata-kata yang
memiliki nilai PMI sangat tinggi dengan w 1. Demikian pula, kita menghitung PMI
β- penjumlahan PMI β- penjumlahan fungsi untuk kata untuk kata untuk kata untuk
kata untuk kata untuk kata w 2. Akhirnya, kita mendefinisikan semantik kesamaan
PMI fungsi antara dua kata, w 1 dan w 2
Kami menormalkan
kata semantik kesamaan (Gambar. 3), sehingga memberikan nilai kesamaan antara 0
dan 1 inklusif. Metode Kata kesamaan adalah modul yang terpisah di Text
Similarity kami Metode. Oleh karena itu metode kata kesamaan lainnya bisa
diganti bukan SOC-PMI. Dalam hal ini, kita perlu mengatur λ dengan nilai
kemiripan maksimum khusus untuk metode tersebut.
3.3 Secara keseluruhan kalimat kesamaan
Tugas kita adalah untuk
memperoleh skor antara 0 dan 1 inklusif yang akan menunjukkan kesamaan antara
dua teks P dan R di tingkat semantik. Ide utama adalah untuk menemukan, untuk
setiap kata dalam kalimat pertama, pencocokan paling mirip di kalimat kedua.
Metode ini terdiri dalam enam langkah berikut:
Langkah 1: Kami menggunakan semua
karakter, tanda baca, dan huruf khusus, jika ada, sebagai batas kata awal dan
menghilangkan semua karakter khusus, tanda baca dan menghentikan kata-kata.
Kami lemmatize setiap kata tersegmentasi untuk menghasilkan token. Setelah
membersihkan kita menganggap bahwa teks
P = {p 1, p 2 ..., p m} memiliki token dan token dan token dan token
dan n ≥ m. Jika tidak, kita beralih P dan R.
Langkah 2: Kami menghitung jumlah, 'S (katakanlah, δ) yang p saya =
r j, p ∈
P dan r ∈ R. Yaitu, ada δ token di P yang sesuai dengan R, dimana δ ≤ m. Kami menghapus semua δ token
dari kedua P dan R. Begitu, P = {p 1, p 2 ..., p mδ} dan R = {r 1, r 2 ..., r
n-δ}. Jika semua persyaratan sesuai, m-δ = 0. Kita lanjutka ke langkah 6
Langkah 3: Kami membangun (m-δ) x
(n-δ) kesamaan string (mengatakan, 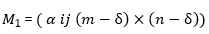 = menggunakan proses berikut: kita asumsikan
tanda apapun p saya ∈ P memiliki τ karakter, yaitu, p i
= { c 1 c 2 ... c τ} dan tanda r j ∈
R memiliki η karakter, yaitu, r j = { c 1 c 2 ... c η} dimana τ ≤ η. Dengan
kata lain, η adalah Panjang lagi
token dan τ adalah panjang token lebih pendek. Kami menghitung berikut:
= menggunakan proses berikut: kita asumsikan
tanda apapun p saya ∈ P memiliki τ karakter, yaitu, p i
= { c 1 c 2 ... c τ} dan tanda r j ∈
R memiliki η karakter, yaitu, r j = { c 1 c 2 ... c η} dimana τ ≤ η. Dengan
kata lain, η adalah Panjang lagi
token dan τ adalah panjang token lebih pendek. Kami menghitung berikut:
= menggunakan proses berikut: kita asumsikan
tanda apapun p saya ∈ P memiliki τ karakter, yaitu, p i
= { c 1 c 2 ... c τ} dan tanda r j ∈
R memiliki η karakter, yaitu, r j = { c 1 c 2 ... c η} dimana τ ≤ η. Dengan
kata lain, η adalah Panjang lagi
token dan τ adalah panjang token lebih pendek. Kami menghitung berikut:
Langkah 4: Kami membangun ( m-δ)
× ( n-δ) semantik kesamaan matriks (mengatakan, M2 = ( β ij) ((m-δ) × ( n-δ)) menggunakan
proses berikut:  dalam baris i dan kolom j posisi pada
matriks untuk semua i = 1 … n- δ dan j = 1 … n- δ
dalam baris i dan kolom j posisi pada
matriks untuk semua i = 1 … n- δ dan j = 1 … n- δ

Langkah
5: Kita membangun (m- δ)x(n- δ) yang lain menggabung matrix  menggunakan
menggunakan  dimana ψ adalaha string pencocokan faktor bobot matriks. φ adalah kesamaan semantik
matriks faktor bobot, dan ψ + φ = 1. Kami menetapkan bobot yang sama untuk
eksperimen kami.
dimana ψ adalaha string pencocokan faktor bobot matriks. φ adalah kesamaan semantik
matriks faktor bobot, dan ψ + φ = 1. Kami menetapkan bobot yang sama untuk
eksperimen kami.
menggunakan dimana ψ adalaha string pencocokan faktor bobot matriks. φ adalah kesamaan semantik
matriks faktor bobot, dan ψ + φ = 1. Kami menetapkan bobot yang sama untuk
eksperimen kami.
Setelah memb∪
γij) jika γij>
0. Kami menghapus semua elemen matriks dari baris ke-i dan ke-j dari M. Kami
mengulangi penemuan nilai maksimum elemen-matriks, γij
menambahkannya ke ρ dan menghapus semua elemen
matriks dari baris dan kolom yang sesuai sampai γij = 0, atau m-δ- | ρ | = 0,
atau keduanya.



Langkah 6: Kami meringkas semua
elemen dalam nilai ρ dan menambahkan δ untuk mendapatkan skor total. Kami
mengalikan skor total ini dengan rata-rata harmonik resiprokal dari m dan n
untuk mendapatkan skor kesamaan yang seimbang antara 0 dan 1, secara inklusif.

4. Evaluasi dan Hasil Eksperimental
Untuk
mengevaluasi ukuran kesamaan teks kami, kami menggunakan dua set data yang
berbeda: 30 pasangan kalimat [20] dan Microsoft paraphrase corpus [6].
4.1 Eksperimen dengan Kesamaan Manusia dari Pasangan Kalimat
Kami menggunakan kumpulan data yang sama
seperti Li et al. [20] (tersedia di
http://www.docm.mmu.ac.uk/STAFF/D.McLean/Sentenc eResults.htm). Li et al. [20]
mengumpulkan peringkat manusia untuk kesamaan pasang kalimat berikut desain
yang ada untuk langkah-langkah kesamaan kata. Para peserta terdiri dari 32
sukarelawan, semua penutur asli bahasa Inggris yang dididik hingga tingkat
sarjana atau lebih. Li et al. [20] dimulai dengan set 65 pasangan kata benda
dari Rubenstein dan Goodenough [36] dan menggantinya dengan definisi mereka
dari kamus Collins Cobuild [4]. Definisi kamus Cobuild ditulis dalam kalimat
penuh, menggunakan kosa kata dan struktur tata bahasa yang muncul secara alami
dengan kata yang dijelaskan. Para peserta diminta untuk mengisi kuesioner,
menilai kesamaan makna pasangan kalimat pada skala dari 0,0 (kesamaan minimum)
hingga 4,0 (kesamaan maksimum), seperti dalam Rubenstein dan Goodenough (R&G)
[36]. Setiap pasangan kalimat disajikan pada lembar terpisah. Urutan penyajian
pasangan kalimat secara acak di setiap kuesioner. Urutan kedua kalimat yang
membentuk masing-masing pasangan juga diacak. Ini untuk mencegah bias yang
diperkenalkan oleh urutan presentasi. Masing-masing dari 65 pasangan kalimat
diberi skor kesamaan semantik yang dihitung sebagai rata-rata penilaian yang
dibuat oleh
peserta Distribusi skor kesamaan
semantik sangat condong ke ujung kemiripan rendah skala. Subset dari 30
pasangan kalimat dipilih untuk memperoleh distribusi yang lebih merata di
seluruh rentang kesamaan. Subhimpunan ini berisi semua pasangan kalimat yang
diberi peringkat 1.0 hingga 4.0 dan 11 (dari total 46) kalimat yang diberi
nilai 0,0 hingga 0,9 dipilih pada interval dengan jarak yang sama dari daftar.
Prosedur terperinci dari persiapan kumpulan data ini ada di [20]. Tabel 1
menunjukkan skor rata-rata kesamaan manusia bersama dengan skor Metode
Persamaan Li et al. Skor kesamaan manusia disediakan sebagai skor rata-rata
untuk setiap pasangan dan telah diskalakan ke dalam kisaran [0..1].

Gbr. 4 menunjukkan bahwa Ukuran
Kesamaan Teks Semantik yang kami usulkan mencapai koefisien korelasi Pearson
yang tinggi sebesar 0,853 dengan rata-rata peringkat kesamaan manusia, sedangkan
Ukuran Kesamaan Li et al. [20] mencapai 0,816. Peningkatan yang kami peroleh
signifikan secara statistik pada level 0,053. Dalam percobaan penjurian manusia
dari Li et al. [20] peserta manusia terbaik memperoleh korelasi 0,921 dengan
rata-rata peserta dan peserta terburuk diperoleh 0,594.
4.2 Eksperimen dengan Microsoft
Paraphrase Corpus
Kami menggunakan metode kesamaan
teks semantik untuk secara otomatis mengidentifikasi apakah dua segmen teks
adalah parafrase satu sama lain. Kami menggunakan Microsoft paraphrase corpus
[6], yang terdiri dari 4.076 pelatihan dan

Gambar 4. Korelasi kesamaan.
1.725 pasangan uji, dan tentukan
jumlah pasangan parafrase yang diidentifikasi dengan benar dalam korpus
menggunakan ukuran kesamaan teks semantik. Pasangan parafrase dalam korpus ini
diberi label oleh dua annotator manusia yang menentukan apakah dua kalimat
dalam pasangan adalah parafrase yang secara semantik setara atau tidak.
Kesepakatan antara hakim manusia yang memberi label pasangan calon parafrase
dalam kumpulan data ini diukur sekitar 83%, yang dapat dianggap sebagai batas
atas untuk tugas pengenalan parafrase otomatis yang dilakukan pada kumpulan
data ini.
Kami mengakui, seperti
dalam [5], bahwa ukuran kesamaan semantik untuk teks pendek adalah langkah yang
perlu dalam tugas pengenalan parafrase, tetapi tidak selalu cukup. Mungkin ada
kasus-kasus ketika makna yang sama diekspresikan dalam satu kalimat dan makna
sebaliknya yang tepat dalam kalimat kedua (misalnya dengan menambahkan kata
tidak). Untuk situasi ini diperlukan metode penalaran yang lebih dalam.
Kami
mengevaluasi hasil dalam hal akurasi, jumlah pasangan diprediksi dengan benar
dibagi dengan jumlah pasangan. Kami juga mengukur presisi (P = TP / (TP + FP)),
recall (R = TP / (TP + FN)) dan F-mengukur (F = 2PR / (P + R)). Di sini, TP,
FP, dan FN masing-masing mewakili True Positive, False Positive, dan False
Negative.
Kami menggunakan
sebelas ambang kesamaan yang berbeda mulai dari 0 hingga 1 dengan interval 0,1.
Dalam Tabel 2, ketika kami menggunakan skor ambang kemiripan 1 (mis.,
Pencocokan kata demi kata secara tepat, oleh karena itu tidak diperlukan
pencocokan kemiripan semantik), kami memperoleh nilai penarikan 0,0044 untuk
kumpulan data uji. Kami dapat menganggap skor ini sebagai salah satu baseline.
Mihalcea et al. [30] menyebutkan dua garis dasar lainnya: Berbasis vektor dan
Acak. Lihat Tabel 3 untuk hasil dari baseline ini dan hasil dari beberapa
metode dari [30] dan [5] (pada set tes).
Untuk tugas
identifikasi parafrase ini, kita dapat mempertimbangkan metode STS yang kami
usulkan sebagai metode yang diawasi. Menggunakan set data pelatihan, kami
memperoleh akurasi terbaik dari 72,42% ketika kami menggunakan 0,6 sebagai skor
ambang kesamaan. Oleh karena itu kami dapat merekomendasikan ambang ini untuk
digunakan pada set tes, mencapai akurasi 72,64% (metode kami memperkirakan 1369
pasangan sebagai benar, dari yang 1022 pasangan benar di antara 1725 pasangan
beranotasi secara manual). Hasil kami pada set tes ditunjukkan pada Tabel 3.
Untuk setiap
pasangan pasangan parafrase dalam set tes, pertama-tama kita menghitung skor
kesamaan teks semantik menggunakan (4), dan kemudian memberi label pada
pasangan kandidat sebagai parafrase jika skor kesamaan melebihi ambang batas
0,6. Kami mendapatkan ukuran-F yang sama (81%) pada metode gabungan dari [30]
dan [5]. Kami memperoleh akurasi dan presisi yang lebih tinggi dengan biaya
pengurangan recall.
Tabel 2. Karakteristik set data evaluasi parafrase dan hasil kami

5. Kesimpulan
Metode STS kami yang diusulkan
mencapai koefisien korelasi Pearson yang sangat baik untuk kumpulan data 30
kalimat dan mengungguli hasil yang diperoleh oleh Li et al. [20]
(peningkatannya signifikan secara statistik). Untuk tugas pengenalan parafrase,
metode STS yang kami usulkan melakukan mirip dengan metode kombinasi tanpa
pengawasan [30] dan metode pengawasan terbimbing [5]. Keuntungan utama dari
sistem kami adalah bahwa ia memiliki kompleksitas dan waktu berjalan yang lebih
rendah daripada sistem lainnya [20], [5], [30], karena kami hanya menggunakan
satu ukuran berbasis corpus, sementara mereka menggabungkan keduanya berbasis
corpus dan langkah-langkah berbasis WordNet. Misalnya, Mihalcea et. al [30]
menggunakan enam ukuran berbasis WordNet dan dua berbasis corpus tindakan.
Kompleksitas dari algoritma dan waktu berjalannya diberikan terutama oleh
jumlah pencarian di dalam corpus dan di WordNet. Kami sama sekali tidak
menggunakan WordNet, karena itu menghemat banyak waktu. Kami menambahkan ukuran
kesamaan string, tetapi ini sangat cepat, karena kami menerapkannya pada string
pendek (tidak perlu pencarian).
Metode kami dapat digunakan
sebagai tidak diawasi atau diawasi. Untuk tugas kedua, pengenalan parafrase,
kami menggunakannya sebagai diawasi, tetapi hanya untuk menemukan ambang batas
terbaik. Untuk tugas pertama, membandingkan skor kesamaan kalimat kami dengan
skor yang diberikan oleh hakim manusia, sistem kami digunakan sebagai tanpa
pengawasan (tidak ada data pelatihan yang tersedia).
Tabel 3. Hasil kesamaan teks untuk identifikasi uraian

Tidak ada komentar:
Posting Komentar